Um die Qualität eines Informationssystems zu beurteilen, legt man im
Information Retrieval (IR) ![]() das Konzept der Relevanz zugrunde. Die
Relevanz beschreibt dabei die Beziehung zwischen der Anfrage und einem
einzelnen Treffer in der Antwortmenge (siehe [Fuh97]).
das Konzept der Relevanz zugrunde. Die
Relevanz beschreibt dabei die Beziehung zwischen der Anfrage und einem
einzelnen Treffer in der Antwortmenge (siehe [Fuh97]).
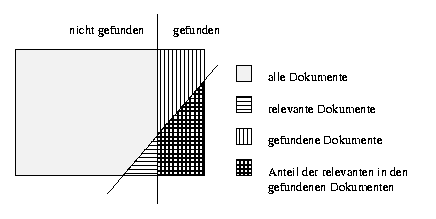
Abbildung: Maße für Boolesches Retrieval
Das Konzept der Relevanz wird in der Abbildung 2.1 verdeutlicht. Der Benutzer stellt eine Anfrage. Das System sucht in der gesamten Datenbank (Menge aller Dokumente) nach den für die Anfrage relevanten Dokumenten. Als Ergebnis gibt das System eine Menge an gefundenen Dokumenten (Treffermenge) aus. Für den Benutzer ergeben sich die folgenden Fragen:
Der Benutzer sieht sich die gefundenen Dokumente nacheinander an und bewertet sie. Die Bewertung geschieht nach einem einfachen Schema: entweder sind die Dokumente relevant zur gestellten Anfrage, oder sie sind es nicht.
![]()
Die Precision gibt den Anteil der relevanten an den gefundenen Dokumenten wieder.
![]()
Recall bezeichnet den Anteil der relevanten in den gefundenen Dokumenten.
Die Größe der Precision ist für jeden Benutzer eines Informationssystems direkt ersichtlich. Er sieht sich die gefundenen Dokumente an und bestimmt das Verhältnis der relevanten zu den gefundenen Dokumenten. Die Größe des Recall ist dagegen für einen Benutzer nicht erkennbar. Der Grund hierfür liegt in der Schwierigkeit, die Menge der relevanten Dokumente präzise zu bestimmen. Dies ist mit vertretbarem Aufwand nicht möglich (siehe [Fuh97]).
Der Wunsch, alle Suchanfragen bedienen zu können (hoher Recall) und dabei wenig irrelevante Dokumente zu liefern (hohe Precision), läßt sich kaum erfüllen. Will man alle relevanten Dokumente finden, so muß man in Kauf nehmen, daß auch nicht relevante Dokumente gefunden werden. Auf der anderen Seite - will man nur relevante Dokumente geliefert haben (hohe Precision) - verringert sich die Anzahl der gefundenen Dokumente, und man ignoriert eventuell andere relevante Dokumente. In der Praxis wird man versuchen, einen Mittelweg zwischen Precision und Recall zu wählen.
Es bietet sich an, nicht nur in einer Datenbank zu suchen. Falls das
gewünschte Buch nicht in der einen Bibliothek vorhanden ist, so findet man es
vielleicht in der nächsten oder übernächsten Bibliothek. Der Benutzer
trifft eine Vorauswahl von Datenbanken, von denen er annimmt, daß sie
für seine Anfrage geeignet sind. Beispielsweise erwartet man ein
deutschsprachiges Buch eher in einer deutschen Bibliothek und nicht einer
amerikanischen Bibliothek zu finden. Ein mathematisches
Buch wird man eher in einer mathematischen Spezialbibliothek
als in einer Allgemeinbibliothek erwarten.
Bei der Suche in zwei Datenbanken addieren sich die Anzahl aller vorhandenen Dokumente. Ein Teil der Dokumente ist in beiden Bibliotheken vorhanden (siehe Abbildung 2.2).
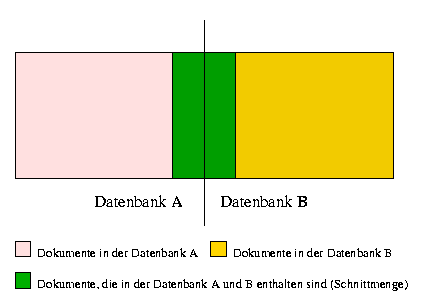
Abbildung: Bestand der Datenbanken A und B
Ebenfalls addieren sich die Anzahl der relevanten Dokumente in beiden Datenbanken und die Anzahl der gefundenen Dokumente bei der verteilten Suche (siehe Abbildung 2.3).
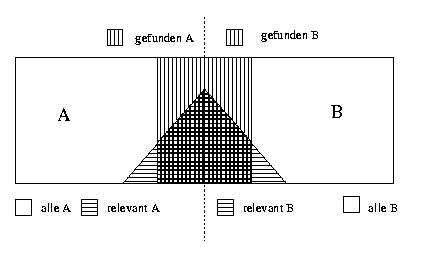
Abbildung: Relevanz bei verteilter Suche
Die Bewertung der gefundenen Dokumente ist bei der verteilten Suche aufwendiger geworden. Es gibt mehr gefundene Dokumente. Der Benutzer muß nicht nur zwischen relevanten und nicht relevanten Dokumenten unterscheiden, sondern auch die in beiden Datenbanken gefundenen Dokumente (Dubletten) herausfiltern (siehe Abbildung 2.4).
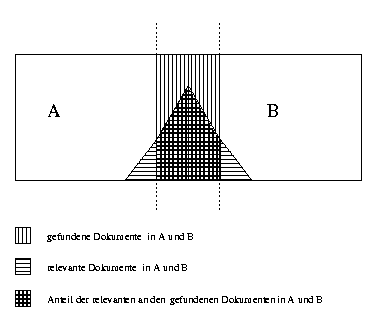
Abbildung: Relevanz bei verteilter Suche mit Dublettenkontrolle
Das in dieser Diplomarbeit entwickelte System ZACK ist ein
WWW-Z39.50-Gateway und übernimmt die Dublettenkontrolle
für den Benutzer automatisch.
ZACK erkennt anhand vorgegebener Kriterien, ob es
sich um gleiche oder ähnliche Dokumente handelt und bietet dem
Benutzer eine übersichtliche Kurztrefferliste der gefundenen
Dokumente. Die Anzahl der gefundenen Dokumente wird deutlich
reduziert (siehe Kapitel 6 Dublettenkontrolle,
Seite ![]() und Kapitel
7 Ausgabe von Dubletten, Seite
und Kapitel
7 Ausgabe von Dubletten, Seite ![]() ).
).
Der Benutzer muß in ZACK bei der verteilten Suche nur noch zwischen den zur Anfrage relevanten Dokumenten und nicht relevanten Dokumenten unterscheiden. Bei der verteilten Suche in mehreren Datenbanken addiert sich die Anzahl der relevanten Dokumente. Für den Benutzer erhöht sich damit die Wahrscheinlichkeit, daß die gewünschte Information auch tatsächlich gefunden wird (Nutzen). Dabei sind die Kosten für den Benutzer (Zeitaufwand) bei der verteilten Suche mit Dublettenkontrolle nur minimal höher als bei der Suche in nur einer Datenbank.
Das System ZACK wird im Kapitel 3 Modellierung
(Seite ![]() ) und Kapitel 4
Implementierung (Seite
) und Kapitel 4
Implementierung (Seite ![]() ) detailliert
beschrieben.
) detailliert
beschrieben.