Für die Dublettenkontrolle müssen die gefundenen Datensätze miteinander verglichen werden. Im einfachsten (und ungünstigsten Fall) wird jeder Datensatz mit jedem verglichen. Dafür sind
![]()
Vergleiche nötig. Die Anzahl der Vergleiche wächst quadratisch mit der Anzahl der Datensätze (O2). Für den Vergleich von 10 Datensätze sind 45 Vergleiche notwendig, bei 30 Datensätze sind es bereits 435 Vergleiche.
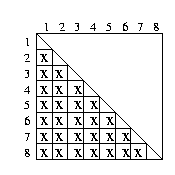
Abbildung: Aufwand Algorithmus vergleiche jeden Datensatz mit jedem
In der Abbildung 6.5 werden 8 Datensätze jeweils miteinander verglichen. Es werden insgesamt 28 Vergleiche durchgeführt. Der Buchstabe ``x'' steht in diesem Beispiel für einen Vergleich, leere Felder für stehen für kein Vergleich.
Mit einem temporären Index kann man die Anzahl der notwendigen
Vergleiche deutlich reduzieren. Man trifft eine Vorauswahl von
Datensätzen, die eine gewisse minimale Ähnlichkeit miteinander haben
(Cluster). Nur diese werden dann miteinander verglichen und nicht mehr
jeder Datensatz mit jedem.
In ZACK wird die Vorauswahl von ähnlichen Datensätzen nach einer einfachen Bedingung getroffen: Es müssen zwei der bei der Dublettenkontrolle verwendeten Attribute (z.B. Titel, Autor, Verlag, Verlagsort, Jahr, Seitenzahl) genau übereinstimmen.
Die Vorauswahl von Datensätzen (Clusterbildung) wird an den folgenden fiktiven Beispielen in den Abbildungen 6.6 und 6.7 verdeutlicht. In beiden Beispielen werden 8 Datensätze auf Dubletten überprüft.
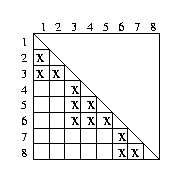
Abbildung: Aufwand optimierter Algorithmus mit Index, Beispiel 1
In der Abbildung 6.6 wird eine Vorauswahl von minimal ähnlichen Datensätzen getroffen. Es werden die Cluster mit den Datensätzen {1, 2, 3}, {3, 4, 5, 6} und {6, 7, 8} gebildet. Insgesamt sind jetzt nur noch 12 Vergleiche notwendig.
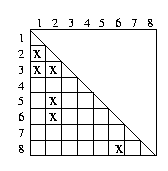
Abbildung: Aufwand optimierter Algorithmus mit Index, Beispiel 2
Zweites Beispiel: in der Abbildung 6.7 wird eine Vorauswahl von minimal ähnlichen Datensätzen getroffen. Es werden die Cluster mit den Datensätzen {1, 2, 3}, {2, 5, 6} und {6, 8} gebildet. Insgesamt sind jetzt nur noch 6 Vergleiche notwendig.
Die Effizienz der Clusterbildung hängt von den verwendeten
Algorithmen und der Zusammensetzung der Datensätze ab.
Der Algorithmus für die Clusterbildung und den temporären Index in
ZACK wird in der Tabelle 6.4 untersucht
(siehe auch Abbildung 6.8). Dazu werden
5 Anfragen nach einem Titel und 2 nach einem Autor an die Datenbanken
der Deutschen Bibliothek (DDB), des Gemeinsamen Bibliotheksverbundes
(GBV), des Bibliotheksverbundes Bayern (BVB) und der Technischen
Universität Braunschweig (TUBS) gestellt (siehe auch Kapitel Normierung,
Seite ![]() ). Ziel ist es festzustellen,
wie effizient der Algorithmus in der Praxis ist.
). Ziel ist es festzustellen,
wie effizient der Algorithmus in der Praxis ist.
| Anfrage | Anzahl | Vergleiche | Vergleiche | in Pro- | Vergleiche | Zeit in | ||
| Treffer | ZACK Index | zent | pro Treffer | Sekunden | ||||
| titel=akazie | 60 | 1.770 | 172 | 9,7 % | 2,9 | 0,5 | ||
| titel=birnbaum | 342 | 58.311 | 6.704 | 11,5 % | 19,6 | 5,6 | ||
| titel=karstadt | 61 | 1.830 | 216 | 11,8 % | 3,5 | 0,4 | ||
| titel=pankow | 212 | 22.366 | 820 | 3,7 % | 3,9 | 1,4 | ||
| titel=perl | 345 | 59.340 | 5.154 | 8,7 % | 14,9 | 5,3 | ||
| autor=dalitz,wolfgang | 28 | 378 | 254 | 67,2 % | 9,1 | 0,6 | ||
| autor=rusch,beate | 9 | 36 | 24 | 66,7 % | 2,7 | 0,2 |
Tabelle: Dublettenkontrolle in ZACK : Aufwand und Rechenzeit mit Index
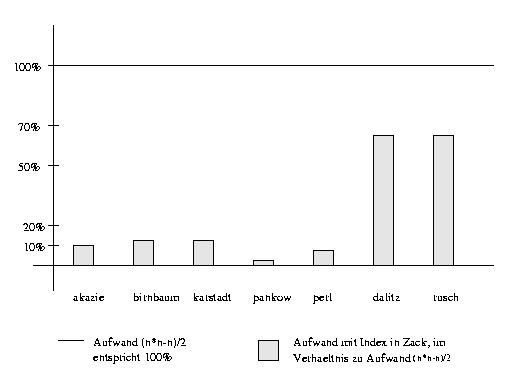
Abbildung: Aufwand mit Index im Verhältnis zu
vergleiche jeden Datensatz mit jedem